
写在前面:本文改写自 AI 研究者 @0xCodila 于 2026 年 7 月 1 日发布的长文《Loop Engineering: The Karpathy Method》,原文一周内近 83 万阅读。傻狗频道在原文基础上补充了背景知识、人物介绍和延伸解读。
你可能还停留在 2005 年的用法
先问自己一个问题:你现在用 AI,是不是还是这个流程——打字、看它回答、再打字、再看?
作者说了一句很扎心的话:大多数人用 AI 的方式,和 2005 年用 Google 搜索没有本质区别。你敲一句话,它给一个结果,然后停在那儿等你下一次动手。AI 什么都不做,除非你去推它——你才是那台发动机,AI 只是你每回合拿起来、又放下去的一把扳手。
这套用法两年前还够用。现在不够用了。
真正从 AI 身上多榨出十倍产出的那批人,靠的不是更会写提示词,也不是拿到了什么内部模型。他们在做一件事:搭循环(building loops)。而把这个概念砸进所有人视野的,是 Andrej Karpathy。
顺带介绍一下这位人物,很多不做技术的读者可能没听过:Karpathy 是 OpenAI 的创始团队成员之一,后来做过特斯拉的 AI 总监(自动驾驶那套神经网络很多是他手上跑出来的),离开特斯拉后又回过 OpenAI,现在自己开了一家叫 Eureka Labs 的公司做 AI 教育。他不是那种炒概念的博主,他的每一次公开发声,硅谷都会认真当回事——这也是为什么这次他随手扔出来的一个 GitHub 仓库,能在一个月内被点了 6.6 万颗星。有个好玩的冷知识:现在到处都在说的「vibe coding(氛围编程,靠感觉跟 AI 你来我往地写代码)」这个词,也是他在 2025 年一条推文里造出来的。这次的「循环工程」,某种程度上是他给自己造的这个词写的续集——上一次是教大家怎么跟 AI 对话写代码,这一次是教大家怎么干脆不对话,让 AI 自己闭环把代码写完。
这套「让 AI 自己循环干活」的想法其实并不新鲜。2023 年那波 AutoGPT、BabyAGI 也喊过一模一样的口号,当时同样火了一阵,最后大多不了了之——核心原因是那时候的模型不够强,缺乏可靠的验证机制,代理很容易在没人看着的情况下跑偏、卡死或者自娱自乐地空转。Karpathy 这次能做成,本质上不是想法变了,是两个前提条件终于成熟了:模型本身靠谱到能被信任无人值守地跑,加上一个足够硬的客观验证指标(模型训练损失能不能真的往下走)。同一个想法,两年前是噱头,现在是生产力。
这篇文章要讲清楚四件事:什么是循环、Karpathy 是怎么用的、有没有比他更猛的做法(有,而且效果是 5 倍)、普通人怎么现在就上手试一次。
第一部分:先搞懂「循环」到底是什么
一句指令(prompt)是什么?你问一句,它答一句,下一步怎么走由你决定。
而循环(loop)是给 AI 定一个目标,让它自己朝这个目标反复干,直到干成——你不用坐在电脑前每一步都盯着。AI 自己发现要做什么、自己规划怎么做、自己动手、自己检查结果,如果还没达标,就把结果喂回去,再来一轮。你只需要把「目的」定义一次,剩下的交给循环自己跑。
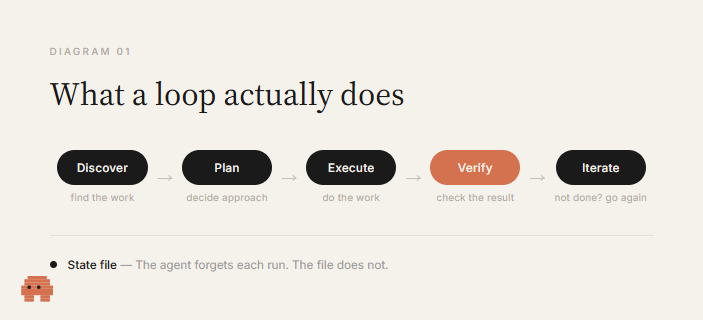
作者拆出了三个决定循环成不成立的关键部件,这三个我觉得是全文最该记住的东西:
第一,验证者(verifier)。没有一个真实的检验标准,你搭的根本不是循环,是一个 AI 在自己跟自己反复点头。这个检验可以是一个能跑通或跑不通的测试、一个能涨能跌的指标、一次能编译能崩溃的构建。没有这道闸门,等于让代理自己给自己的作业打分——分数当然永远是满分。
第二,状态(state)。循环能不能「学习」,取决于每一轮它是不是知道自己上一轮试过什么。没这个机制,它会一遍一遍犯同一个错。解法很简单:留一个小文件,记下已经做完的、失败过的、接下来要做的。第二天接着跑的时候,是从上次的进度续上,而不是从零开始。
第三,停止条件(stop condition)。一个没有出口的循环,会一直跑到成功、跑到崩溃,或者跑到把你账户的钱烧光为止。任何一个能用的循环都得有两条退出路径:目标达成了,或者一条硬性规则说「试了 N 次还不行,就停下来跟我汇报」。
你到底需不需要搭一个循环?先做这个自测
大多数讲循环的文章,都是先把循环卖给你,然后才告诉你什么时候不该用它。作者给了一个四条自测清单,四条全部满足,循环才划算;漏一条,它花的成本就会比省下来的多:

作者说得很实在:循环工程是真的有用,但大多数人现在还不需要重型版本。如果你在用消费级套餐、token 有限,一个重型循环还没等你看到生产力提升,就先把你的速率限制或者钱包撞穿了。
第二部分:Karpathy 循环——他是怎么从「打字」变成「挂机」的
2026 年 3 月,Andrej Karpathy 放出了一个 GitHub 仓库,名字叫 AutoResearch。三个文件,大约 630 行代码。一个月不到,星标数破 6.6 万,《财富》杂志专门给它起了个名字:Karpathy 循环(The Karpathy Loop)。
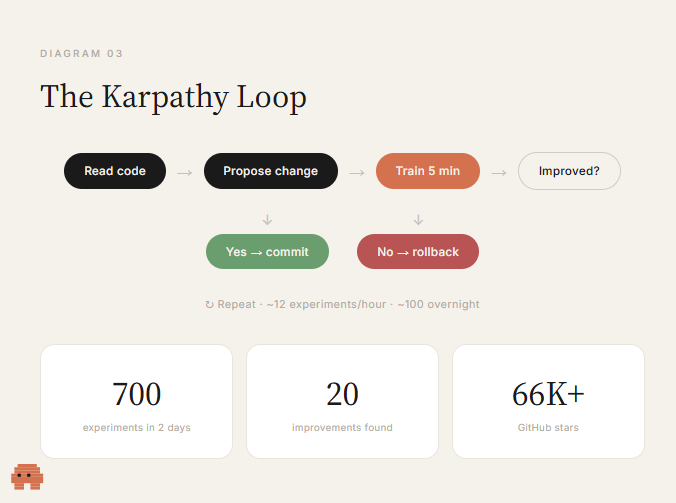
这套东西的搭建方式简单到有点离谱:
代理就在这个框架里循环运转:读代码 → 提出一个改动 → 训练五分钟 → 检查结果有没有变好 → 好就提交,不好就回滚 → 再来一轮。你去睡觉,第二天醒来看到一份实验日志,运气好的话,还有一个更好的模型。人类从头到尾没碰过 train.py 这个文件——你写 program.md,剩下的全部交给代理执行。
跑出来的结果是什么? Karpathy 把这套东西对准了一个他自己已经手动调了二十年经验的模型,让它跑了两天:
为什么人会漏掉?因为人做到第十二次实验就开始疲了。代理完全不会累。
Shopify 的 CEO Tobi Lütke 也拿这套方法在自己的内部模型上试了一整晚,第二天早上收获:19% 的质量提升,而且优化后的模型体积只有原来的一半——一个更小的模型打赢了更大的模型,因为代理是在为硬件做优化,而不是默认「越大越好」这个人类的思维惯性。
Karpathy 这次分享里最核心的一句话,我觉得值得所有做技术决策的人反复咀嚼:如果你手上有一个客观、可量化的指标,那跑实验的就不该是你自己。你才是那个瓶颈。把自己从循环里移出去,让它自己跑。
第三部分:搭一个循环,需要哪五块积木
不管你是在 Claude Code、Codex 还是自己写的 bash 脚本里搭循环,能跑起来的循环都是由五个部件拼出来的——而且 Claude Code 和 Codex 现在都已经把这五个部件配齐了。

自动化(Automation)——循环的心跳。按周期触发、按事件触发、按条件触发,总得有个东西按下启动键。Claude Code 里对应 「/loop」(按节奏跑)和「/goal」(跑到条件满足为止);Codex 里是 Automations 面板。没有这颗心跳,你只是跑了一次脚本然后忘了它,那不叫循环。
技能(Skill)——把项目知识存下来,让代理不用每次都从零猜。你的代码规范、你的构建步骤、三个月前那次事故之后你就再也不做的那件事——写进一份 Markdown 文件,一次写好,每一轮都被读取。没有技能沉淀,循环每一轮都要重新推导整个项目背景;有了它,意图会像利息一样复利累积。
子代理(Sub-agents)——把「写的人」和「查的人」分开。写代码的那个模型给自己批改作业总会手松;换一个指令完全不同的第二代理来查,才能抓住第一个代理自己说服自己放过的东西。写的可以又快又便宜,查的可以又慢又严格——这个分离,撑起了循环质量的大半壁江山。
连接器(Connectors)——让循环能在你真实的工作环境里动手,读你的工单系统、开一个 PR、在 Slack 里提醒你、更新一张 Linear 卡片。这是「一个只会说『这是修复方案』的助手」和「一个真的把修复交上去、第二天早上告诉你一声的循环」之间的分界线。
验证者(Verifier)——闸门本身。测试、类型检查、构建,任何能自动判定「这活儿不行」的机制。其余四块都是管道,这一块才是让循环真实存在的东西——没有它,你只是在花钱让一个代理整晚自己跟自己点头。
第四部分:比 Karpathy 更猛的做法——循环之上再套一个循环
这里开始变得有意思了。2026 年 3 月,两位研究者在 arXiv 上发了一篇论文,叫《Bilevel Autoresearch: Meta-Autoresearching Itself》(双层自动研究:对自动研究本身进行元研究)。
他们盯着 Karpathy 那套循环问了一个很简单、但没几个人会去问的问题:如果「自动做研究」本身也是一种研究,那能不能让 AI 反过来对「自动做研究」这件事本身做研究?
他们在原来的循环外面又叠了一层:
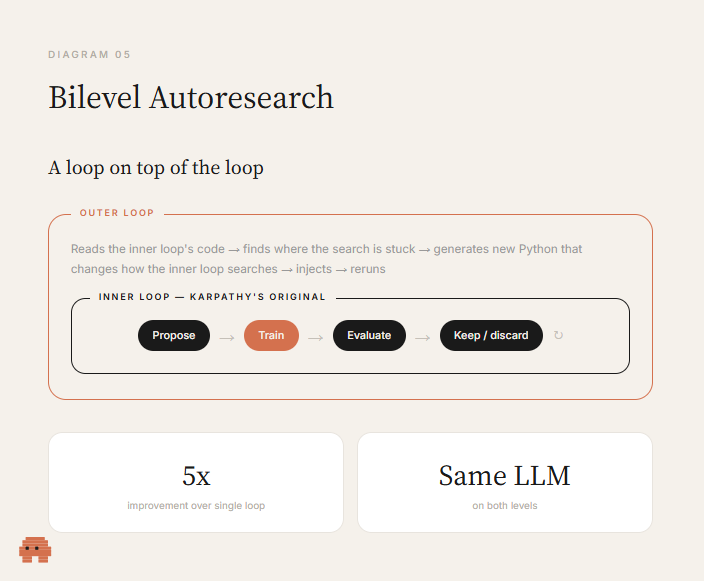
结果有多夸张? 在 Karpathy 那个 GPT 预训练基准测试上,双层结构比单层循环整整快了 5 倍(不是 5%,是 5 倍)。更值得注意的是:两层用的是同一个 LLM——不需要一个更聪明的模型来跑元层级,提升完全来自于架构本身,而不是原始智力的差距。
外层循环到底发现了什么?内层循环会反复陷进同样的搜索模式——LLM 对「该试哪些优化方向」这件事是有先验偏好的,即便这些偏好早就不再管用,它还是会习惯性地回到那几条老路上。外层循环做的事,就是打破这些惯性模式,逼着模型往它本能会回避的方向去探索。
论文结尾那句话我觉得值得所有做 AI 工程的人抄下来:如果自动研究可以对自身进行元研究,那么原则上,它可以对任何有可量化目标的东西进行元研究。
第五部分:不用任何工具,现在就能自己试一次
你不需要 Claude Code 或者 Codex 才能感受这套东西怎么运作。打开任意一个 AI 对话框,构造这样一段指令,就能看到效果:把你要产出的任务写清楚,定几条判定标准(越严格越好),然后让 AI 遵循一套「计划—执行—打分—决定」的固定动作反复跑:每一轮先说清楚下一步要做什么,然后动手产出或改进,接着按你定的标准逐条打分、诚实列出哪里还不够,最后判断——如果每一条都到了高分,就停下收工;只要有一条没达标,就继续下一轮,而且优先修最弱的那一项。你只需要交代一次目标和标准,然后不断催它「继续」,看着它自己把一版半成品磨成一个能打的成品。
这就是一个循环,你只用一段话就搭出来了。当然它还很原始——触发的还是你自己,没有排期,没有持久化的状态记录,关掉对话框它就彻底消失。但它已经把核心机制演示清楚了:从这个雏形走到一个完整的自主循环,中间要补的只是自动化触发、状态文件、和验证闸门这三样东西。
第六部分:诚实的部分——循环解决不了什么
循环改变的是「干活的方式」,不是把你从这件事里彻底删除。而且有两个问题,会随着循环越搭越顺手,变得更严重而不是更轻松:
理解负债(Comprehension debt)。循环跑得越顺、代码交付得越快,你仓库里「实际存在的东西」和你「真正理解的东西」之间的缺口就拉得越大。一个跑得很顺的循环,是在这个缺口上按复利计息——总有一天,团队里没人读过的系统需要有人去 debug,那一天付出的代价,会远超过之前省下的所有 token。
认知放弃(Cognitive surrender)。当循环能自己跑起来,人很容易就此停止形成自己的判断,对回来的结果照单全收。设计循环这件事,你带着判断力去做,它是解药;你为了逃避思考去做,它就是加速器。同一个动作,结果完全相反。
两个人可以搭出一模一样的循环,得到完全相反的结局。一个用它在自己深刻理解的领域里跑得更快,另一个用它彻底逃避理解这件事本身。循环分不清这两者的区别。分得清的,只有你自己。
写在最后
原文结尾那句话,我觉得比全文任何一个技术细节都更值得记住:Karpathy 不再亲手写代码了,Cherny(对,就是傻狗频道之前那篇文章里提到的、Claude Code 的创造者)不再一句一句敲提示词了,但他们俩都没有停止思考。
如果这篇文章你只带走一句话,带走这句:工具在往前跑,但省下来的脑力,从来都应该花在「想清楚要什么、判断结果对不对」这件事上,而不是干脆不想了。
延伸阅读
① Karpathy 那个引爆全网的 AutoResearch 仓库(github.com/karpathy/autoresearch)——三个文件,630 行代码,感兴趣的可以直接去看源码
② 《财富》杂志对这次事件的报道,就是「Karpathy 循环」这个名字的出处
③ 那篇让效果提升 5 倍的《Bilevel Autoresearch》论文原文(arXiv:2603.23420)
④ 原文作者 @0xCodila 的完整长文
原文:《Loop Engineering: The Karpathy Method - and the workflow that just made it 5x better》(@0xCodila,2026-07-01)